Appearance
Chat2API 技术报告
💡 本篇是我们的技术报告,如果您对Chat2API产品感兴趣,请首先阅读Introducing-Chat2API。
下面这张图是我们对某企业的API调用能力进行模型微调后,模型(最右侧)在不同数据集上与主流模型的能力对比。
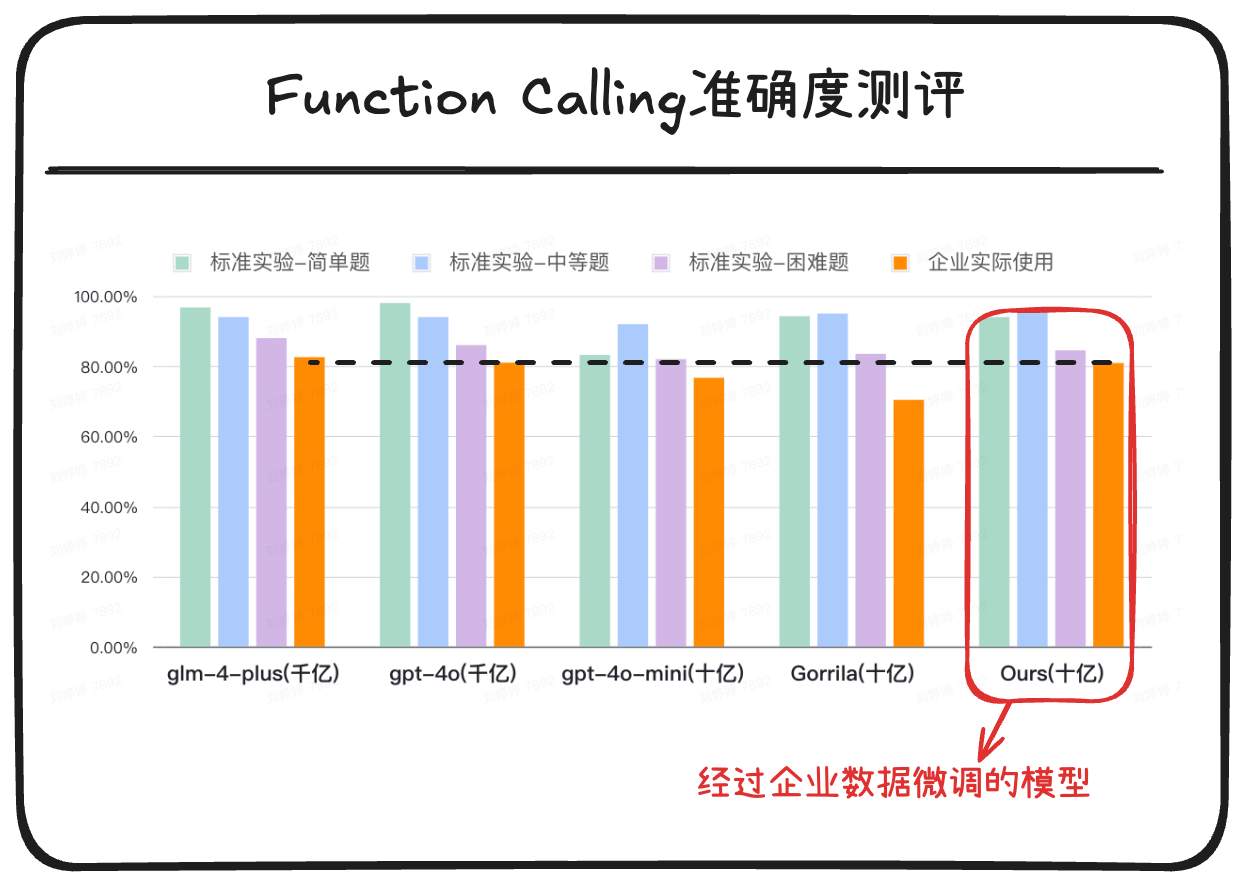
我们看到:
- 在企业最关注的企业实际使用场景测试集(橘色表示)上,经过企业数据专项微调的模型准确率和GPT-4o不相上下,比GPT-4o mini高出5个百分点。
- 然而,和GPT-4o相比,这个模型的参数量只有传说中GPT-4o模型参数量的百分之一。
这一点正是印证了"数据定义模型"的真理,即:什么样的数据就会产生什么样的模型。
🤝 邀请合作
如果您对此感兴趣,可以点击此处预约演示,我们将提供免费算力来助力您训练出企业私有的function calling 模型,推动Agent在企业内部落地。
On this page
- 为什么要做API精准调用?
- 如何做到精准API调用?
- 第一步定义微调基准
- 第二步:构建训练数据集
- 第三步:模型微调
- 第四步:执行测试并评估
为什么要做API精准调用?
对于Agent来说,学会使用工具就像人类使用工具一样重要。我们很难想象人类没有挖掘机,就能建起高楼大厦;同样,Agent没有API调用能力,就只能沦为思想的巨人,行动的矮子。
举个例子,在下图中,针对企业内部的问询,没有工具调用能力,Agent就只能回答"我不知道"。

而对Agent来说,工具中一大部分就是互联网时代构建的API。
今天的用户早已不满足于只能耍嘴皮子的AI,他们更希望AI能真正做点事,比如:
- 当客户反馈故障时,可以根据具体情况自动安排上门维修的时间;
- 当客户开始咨询产品时,Agent能进行初步访谈,确定购买意向,并派发给对应的销售人员跟进;
那么Agent就需要学会调用工单系统的API,CRM系统的API,ERP系统的API,OA系统的API...等等。
如何做到精准API调用?
对于大模型来说,API调用本质上是把自然语言翻译转换为API request,比如:
- 用户说"帮我订个草莓",大模型翻译为:
POST /order/create({"product": "草莓"})- 用户说"帮我查一下我的订单",大模型翻译为:
GET /order/list({"customer_id": "123456"})而用户要使用模型的API调用能力,需要把一个重要东西发给大模型,那就是API的接口定义(下图)。
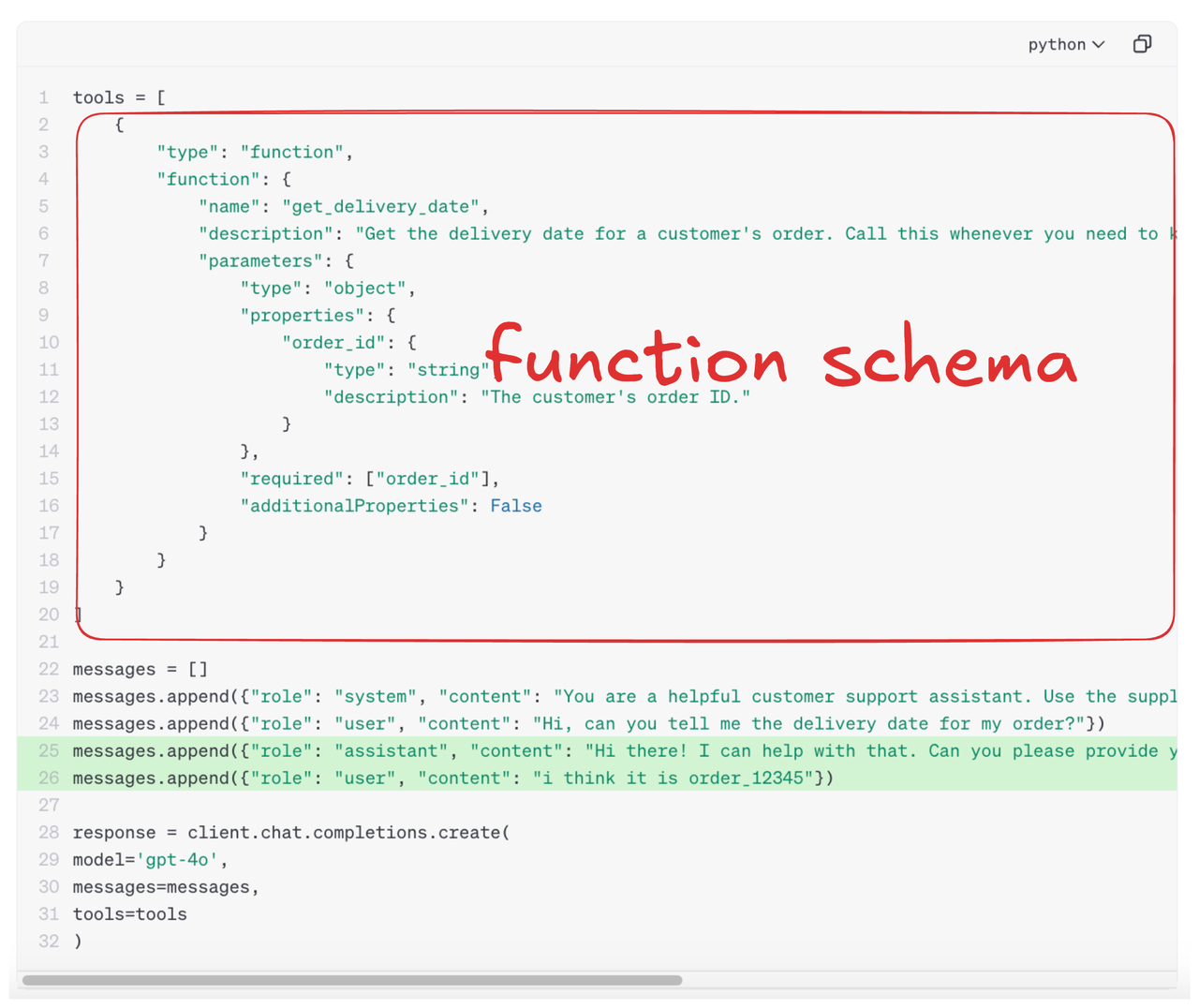
在这里,我们观察到函数调用的能力,本质上考察的是模型的两个能力:
- 语言理解能力:理解并提取自然语言指令中的参数,并匹配到函数的对应参数上。比如把
草莓匹配到product上 - 模式学习能力:生成遵守函数调用格式的文本序列,比如生成半格式化文本
POST /order/create({"product": "草莓"})
而大语言模型最擅长语言理解,微调最擅长模式学习,因此我们可以通过微调大模型来实现API调用能力的增强。以下和大家分享我们的具体操作步骤。
第一步:定义微调基准
📊 基准线定义
没有标准的是没有价值的,一个基准线中需要包含参照对象、测试任务和评测方法。
定义测试基准线就像举行一次考试,需要确定参照对象、考试项目和评测方法。
首先,定义参照对象
我们选择了以下参照对象:
- 国内智谱GLM-Plus-4(千亿级参数)
- 海外的OpenAI GPT-4o(千亿级参数)
- GPT-4o-mini(十亿级参数)
- 伯克利大学的Gorrila(6.9B参数)
其次,定义测试任务(考试项目)
我们定了四个难度的任务,分别是:
- 标准实验-简单题:API接口结构简单,只提供单个接口定义,单条自然语言指令,模型在函数调用时无需选择接口。
- 标准实验-中等题:API接口结构简单,提供多个接口定义,单条自然语言指令,模型在函数调用时需要从多个接口中选择一个接口。
- 标准实验-困难题:API接口结构简单,提供多个接口定义,多条自然语言指令,模型在函数调用时需要从多个接口中选择不同接口完成多个指令。
- 企业实际场景:API接口结构复杂,提供多个接口定义,多条自然语言指令,模型在函数调用时需要从多个接口中选择不同接口完成多个指令。在这里我们采用小鹅通开放接口作为实验集。可以看到它更接近于企业中真实使用的API结构,比如在下面的接口定义中,接口参数中有指定众多枚举值的,有List结构,还有嵌套结构。
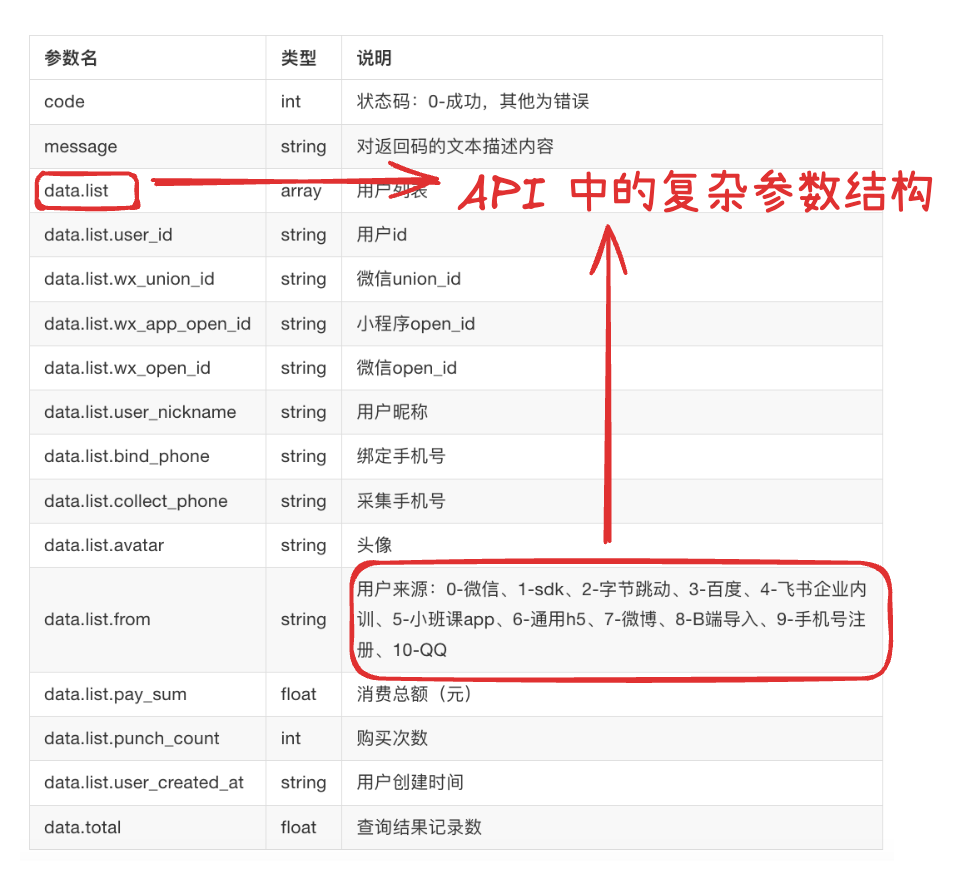
在上述这四个任务中,每个任务都要包含若干测试集。前三个任务的数据集采用开源模型Gorrila的公开数据集。第四个任务的数据集需要我们自己来构建,稍后会有构建过程。
然后,确定评估方法。
当前,大多数语言模型的默认评估指标Predict_bleu-4, predict_rouge-x,主要考察实际输出与期待输出之间的文本重合度。
但在API调用的评估中,我们希望能做到:完全准确。完全准确的意思是:实际答案与标准答案可以顺序不同,但逻辑不能有误。

因此,我们采用更适合评估函数调用能力的AST(Abstract Syntax Tree 抽象语法树) 方法。AST方法简单来说就是按照函数参数定义按顺序逐步深入检查模型生成的API request是否符合定义,它的检查顺序是这样的:
- 先对比Function选择是否正确
- 检查必填字段是否缺失。
- 检查是否有多余字段。
- 检查数据类型是否一致。
- 检查数据值是否一致。
 来自 Berkeley Function Calling Leaderboard
来自 Berkeley Function Calling Leaderboard
由上看出,AST是严格检查函数参数结构,参数名称、参数类型、参数值是否合乎ground truth的方法, 更适合做function calling准确性的评判。更多AST方法介绍参考这里
第二步:构建训练数据集
数据集的准备往往需要大量人力,在大部分的企业定制模型训练中,这一步也是最耗时、耗力的工作。且数据的准备不是一次性的,数据更新迭代本身就是模型持续改进的基础。
API调用微调的数据集可以是:
- 真实数据集:我们会从海量日志中提取出API request。比如前端的每次点击操作可能会对应着一条指令,同时对应了一次后台的API调用,将二者匹配起来就是一条数据。
- 合成数据集:我们会依据API schema文档合成数据集,然后进行筛选。在这里我们参考了openAI给出的官方指导,同时有针对性地进行了优化。
经过多次的数据集准备后,这部分的工作已经融入在我们的产品中,几乎全部可以由程序完成,您完全不用操心。只需一个API文档,加上少量辅助检查,即可完成训练数据集的准备。在本次案例中,我们完成了2000+条的数据准备。
🤝 邀请合作
如果您对此感兴趣,可以点击此处预约演示,我们将提供免费算力来助力您训练出企业私有的function calling 模型,推动Agent在企业内部落地。
准备完数据集之后,就是微调模型了。
第三步:函数调用操作
模型微调的具体过程如下:
- 选择基座模型:我们选择6.9B参数量的Gorrila模型作为基座模型来微调,主要考虑到企业私有化部署、低成本的诉求。对于这个模型来说,推理仅使用单张4090 GPU即可,微调也只需要两张4090GPU。
- 确定微调数据:我们使用上一步准备好的2000+条数据对。
- 确定微调资源:我们使用丹摩算力租赁平台(单张4090GPU租赁价格约为2元/小时)
- 微调方法:使用开源llamaFactory微调框架进行Lora微调。
第四步:执行测试并评估
我们将第一步得到的API schema文档,加上测试数据集的输入项发给GPT-4o进行测试。同时,为了对比企业真实API的函数调用能力和一些实验数据集,我们对实验数据集也进行了测试。
| 测试场景 | glm-4-plus(千亿) | gpt-4o(千亿) | gpt-4o-mini(十亿) | Gorrila(十亿) | Ours(十亿) |
|---|---|---|---|---|---|
| 标准实验-简单题 | 96.75% | 98.00% | 83.20% | 94.25% | 94.00% |
| 标准实验-中等题 | 94.00% | 94.00% | 92.00% | 95.00% | 95.50% |
| 标准实验-困难题 | 88.00% | 86.00% | 82.00% | 83.50% | 84.50% |
| 企业实际使用 | 82.56% | 81.00% | 76.68% | 70.37% | 80.88% |
📊 测试结果
可以看到:经过2000+条数据微调后,在企业实际使用场景下,准确率由70.37%提升到了80.88%。基于此,我们和某些客户合作进行工程化增强后,准确率可以达到95%。这时我们完全可以:
- 让Agent在高准确率API上放手去做。
- 在准确率尚不完善的API中,仅给出建议,让人工来辅助决策。
完成上述过程(包括数据准备、模型微调和评估)仅仅需要41分钟。
随着人工辅助决策的次数越来越多,这些选择也能作为更好的训练数据,让模型进入不断迭代的过程,构成了Agentic系统与模型的双向驱动,从而适应越来越多的场景。
🤝 邀请合作
如果您对此感兴趣,可以点击此处预约演示,我们将提供免费算力来助力您训练出企业私有的function calling 模型,推动Agent在企业内部落地。