Appearance
Agent接管物理世界的三种方法
人们真的是越来越期待一个能做事的Agent,即通过Agent能调用物理世界的资源完成事情。
- 2024年,OpenAI的开发者大会上,演讲中展示了Agent帮主人订草莓的过程。
- 2024年10月23日,Claude发布了Computer Use功能。
- 2024年10月29日,智谱发布了类似的AutoGLM。
历史演进
如果把历史时间线拉长,我们会看到我们会看到人类从有文明以来就以不同的方式在改变着物理世界。
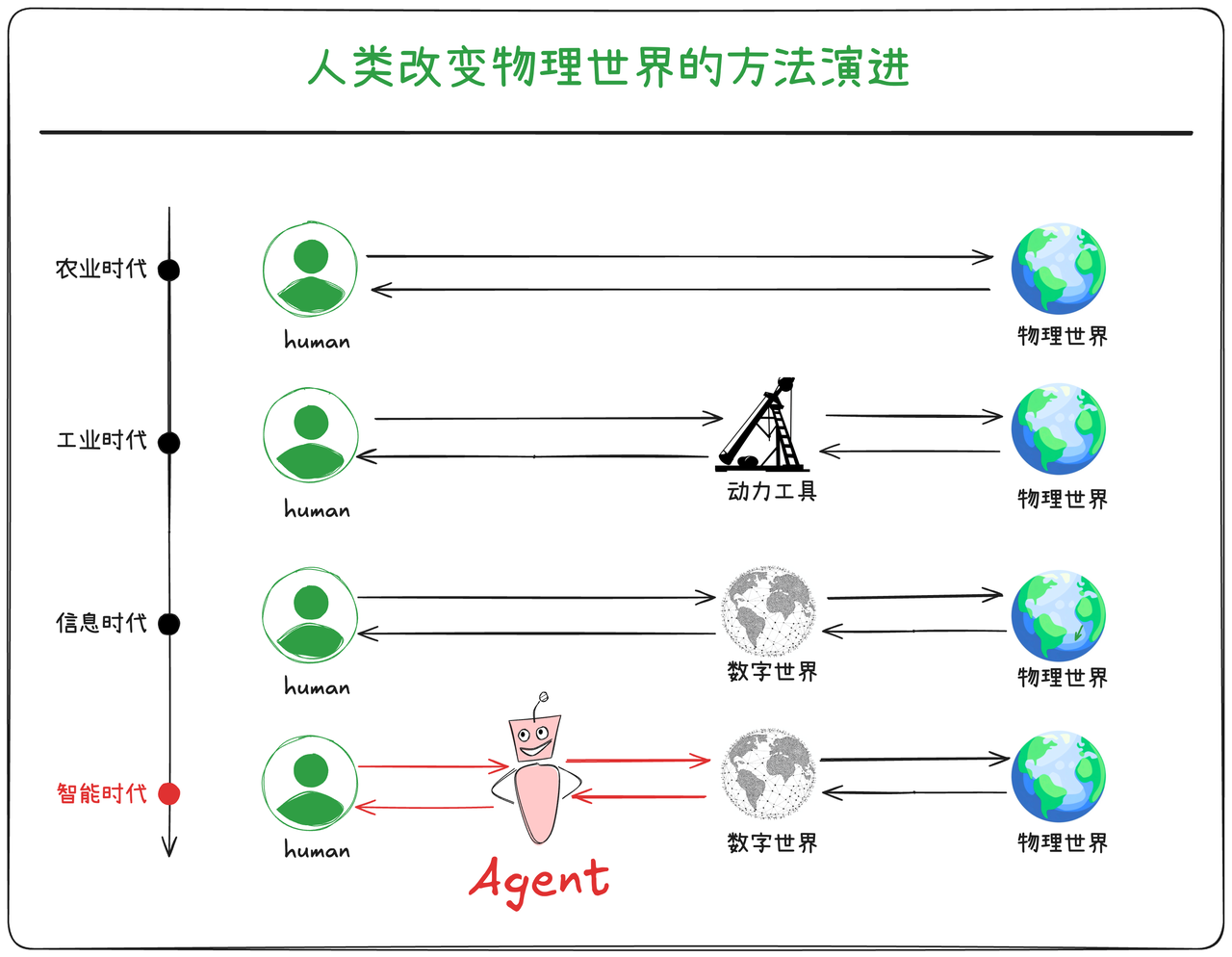
- 农业时代,人类通过种地直接改造物理世界,那时的技术是农垦工具。
- 工业时代,人类通过机器加速了改造物理世界的速度,技术领先者靠出售机器来赚钱。
- 信息时代,人类通过数字世界,扩展了改造物理世界的广度,技术领先者靠出售虚拟世界的服务来赚钱。比如打车App是一个由司机、乘客、出行工具组成的数字世界,我可以通过打车App来控制物理世界中的出行工具。
- 智能时代,人类希望构建出智能体Agent来接管数字世界,扩展了改造物理世界的便利性,那我们就可以通过出售Agent而赚钱。
Agent接管数字世界的三种方式
大体来说:业界目前有三种方式:
- 一是通过视觉操作的方式。
- 二是通过对页面元素进行操作的方式。
- 三是函数调用方式。
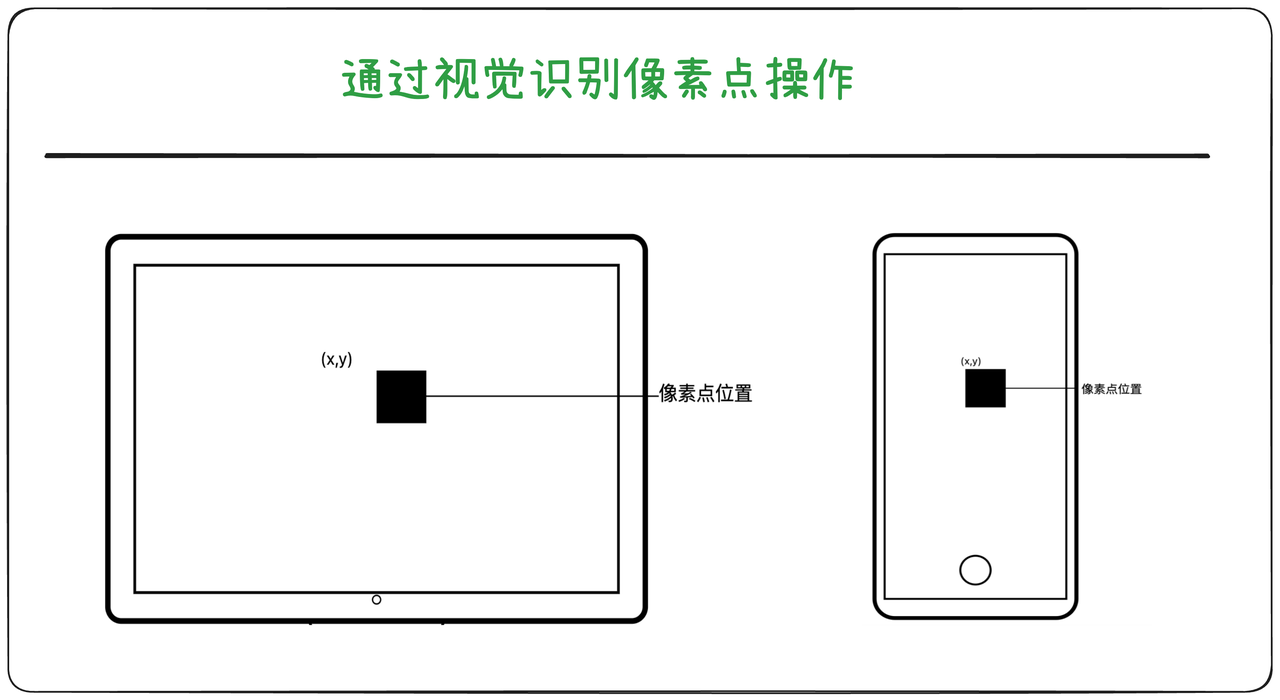
视觉操作
Claude的Computer Use就是这种形态,Claude的官网上这样描述他们的实现方法:
Claude looks at screenshots of what's visible to the user, then counts how many pixels vertically or horizontally it needs to move a cursor in order to click in the correct place.
Claude查看用户可见的屏幕截图,然后计算光标需要在垂直或水平方向上移动多少像素才能点击到正确的位置。它的原理和人类的视觉操作完全一致,看到屏幕上的显示,然后点击。这种方式目前在一个开源数据集中的准确率是多少呢?14.9% [参考],这是Claude的测试结果,而这已经是非常领先了。
HTML元素操作
比如开源的Mind2Web项目会把网页的HTML代码发给大语言模型,从中找到需要操作的页面元素,然后借助JavaScript脚本执行点击等操作。这可以从他们对训练数据的描述中看到:
We have paired each HTML document with the corresponding webpage screenshot image。
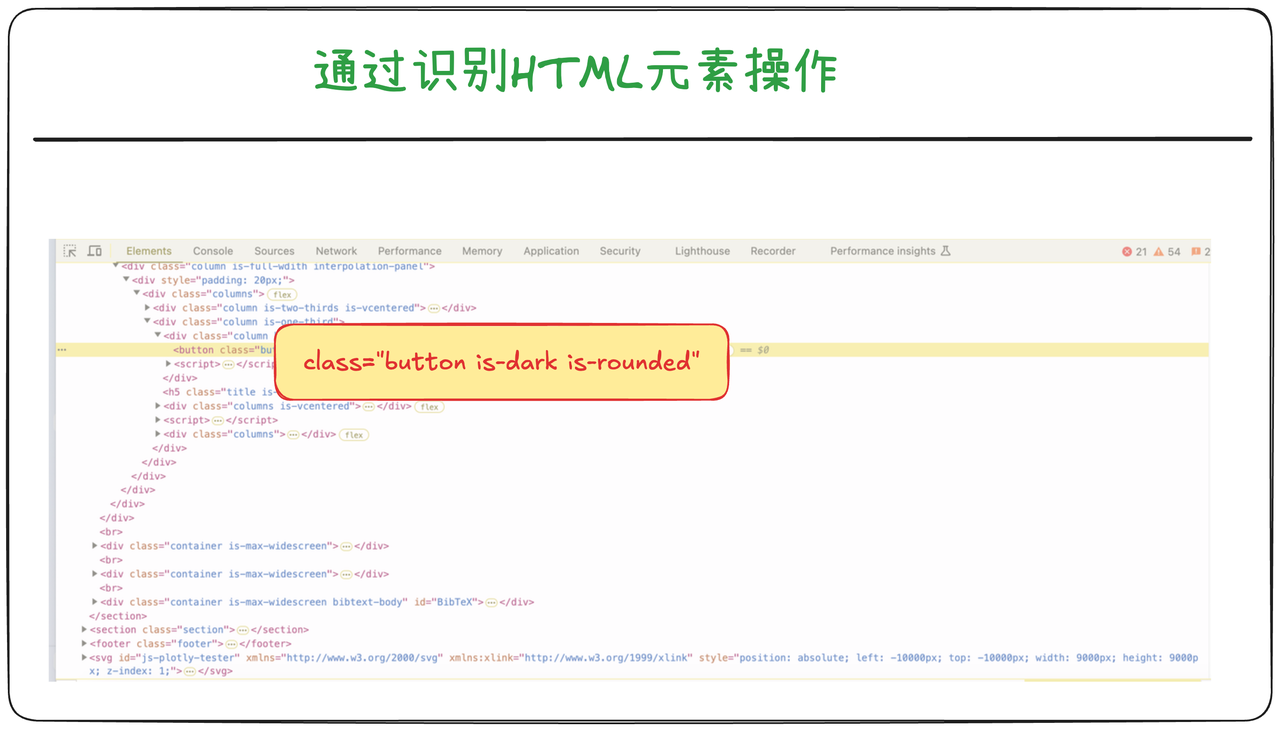
这种方式需要从几百个网页元素中找到正确元素。这个过程中难免会发生提取错误。在Mind2Web项目中,作者收集了137个网站的页面信息,执行了2350个自然语言指令,并记录了这些指令背后的页面操作步骤;随后用这些数据对模型进行微调,网页元素识别的准确率为55%。
另外,这种方式也会把大量的无效信息(几百个网页元素的HTML代码)发送给模型,造成token浪费。我下载了部分数据后发现,仅仅一条自然语言指令对应的数据量大小大约是40万Token数。如果在OpenAI GPT-3.5模型的基础上微调,一条数据要消耗3.2美元,即使前期有压缩,成本依然不能忽视。
函数调用操作
即Agent直接操作数字世界的接口或者函数来实现。
比如通过function calling调用一次查询接口请求实现一次查询操作,这里Agent无需操作页面。关于我们对Function calling的理解可以参考Introducing 【产品名称】
这种方式相比于模拟人类操作的方式的准确率更高,即使是7B参数量的小模型也可以比较轻松地达到80%的准确率,并且通过小微的定制化改善还有提升空间。您可以查看我们的技术报告。
但是,这种方式要求企业有相对完善的接口。在过去十年的数字化转型过程中,很多企业、软件系统已经完成了前后端分离的微服务架构建设,也就是开放了相对完备的接口服务,这也为Agent通过函数调用方式接管数字世界提供了较好的基础。
基于此我们开发了Chat2API产品,它可以帮助企业快速构建自己的函数调用模型,并提供给企业内部使用。
🤝 邀请合作
如果您的企业也希望拥有自己的函数调用模型,可以点击此处 预约演示,我们将提供免费算力来助力您训练出企业私有的function calling 模型,推动Agent在企业内部落地。